|
|
|
|
|
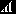 |
 |
|
|
Basic sound theory and synthesis
|
|
|
|
|
|
Intro
Some people have asked for an explanation as to how sfxr produces sounds, and how sound synthesis works in general. I figured I might as well write up a small article on basic sound synthesis from my perspective, which mainly focuses on "retro" sounds along the lines of 80's games consoles and computers.
There's a lot of fluff here, so you may want to skim a bit if you're only interested in some specifics. I have tried not to require any prior knowledge, but some parts are probably not self-explanatory (while others might be exploring the fundamental basics too far thus becoming confusing in their own right).
If something seems weird and hard to make sense of, it probably is. So just skip past it. Most of this was written off the top of my head without too much planning and structuring, so there are bound to be mistakes and bad phrasing. Part of the text is aimed at programmers trying to implement their own audio synthesis, so if you just want the general sound theory you can safely skip those bits.
Please let me know if you find something that is intensely confusing or just plain incorrect.
What is sound?
Sound is what you hear. You hear what your ears capture, and your ears capture subtle and rapid changes in air pressure. These changes in pressure, or pressure waves travelling through the air, typically come from moving objects or parts of objects. If something moves, it pushes on the air in front of it and that causes a wave of pressure that spreads out and grows weaker the further it goes. It's essentially the same phenomenon that can be seen by playing around with your hands on a water surface.
These pressure waves can be of different intensity (experienced as volume, very loud sounds can even be felt in the rest of your body), and they fluctuate back and forth at the same speed as the object that caused them (heard as frequency or pitch). Our ears can interpret sound frequencies ranging between approximately 20 Hz (Hertz) to 20000 Hz (or 20 kHz, for kilo-hertz). One Hertz corresponds to one back-and-forth motion in a second.
A single Hertz can easily be produced by waving your hand back and forth, and it doesn't appear as sound since our ears can't "go that low". It does however generate a movement of air that you can easily feel. If you were able to wave your hand faster, at more than 20 back-and-forths per second, it would start sounding like a very deep bass tone.
As an example of what you actually can hear, a Swedish dial-tone is usually 440 Hz, or the musical note 'A'. That means that it is generated by an object swinging back and forth 440 times each second, which is pretty fast as far as everyday motion goes. Apparently the American equivalent is a mix of two tones at 350 and 440 Hz, but the result is still in the same range.
When sound needs to be illustrated graphically, it's common to use a horizontal time axis and show the position of an imagined moving object on the vertical axis. This means that the graph can be interpreted as a "movie reel" showing how an object would have to move to recreate the sound. For a simple tone, the graph looks like a wavy string, and if you travel to the right in the image you see that the object would move up and down at a regular interval which will correspond to the frequency of the tone.
What about sound synthesis, how do we make sounds?
So, to create sound we apparently need to move an object. Conveniently enough, there are objects widely available that can be moved back and forth in a quick and arbitrary way. They're called speakers. A speaker is basically an electromagnet attached to a mobile cone, in such a way that when a varying electrical signal is fed to it, the cone will move to follow the signal.
The traditional way of creating sounds is to reproduce naturally occuring sounds. This is done using a microphone, which is essentially a reversed speaker, that generates a signal from the sounds it is exposed to. That signal is then either stored or passed directly through an amplifier to one or several speakers. When the speakers receive the signal, they move in the same way as the microphone membrane (cone) moved when it was exposed to the original sound, so the end result is yet again that same sound, but with a small time delay and a modified volume (typically louder).
Reproducing natural sounds is all well and good, but that's not what we're here for. If you want a specific type of sound you'd have to search for a way of generating it using actual physical objects, which can often be close to impossible. Old-school sound effect technicians in movie production have done some remarkable work with hands-on physical sound generation though. Popular examples are the Tie Fighter laser sound from Star Wars (hitting metal wires) and the T-Rex growl in Jurassic Park (large moving machinery, a flight simulator I believe). Obviously there are infinite other effects ranging from explosions to monster noises and of course the ever-popular fist fights.
Most of these aim to capture "life-like" sounds in some way though - things that could potentially be heard in the real world. For imaginary sounds that have no correlation to the real world, it would be handy to bypass the microphone stage completely and just create our own electrical signal for the speakers.
Once again, there are convenient systems in place for this. A computer soundcard has what's called a digital-to-analog converter (D/A or DAC), which is able to generate an electrical signal from a digital number that is given to it. The number must be within a certain range, say -1.0 to +1.0 (with arbitrary precision in between). Generally, zero gives us the rest/idle position of the speaker element, and positive numbers push it forward while negative numbers push it back in the other direction. It doesn't actually matter a whole lot which way it goes though, as the sound you hear will be more or less the same (an object swinging back and forth is both "back" and "forth", just at different times... so by looking at a large number of repetitions, you can't really tell if it's "upside down" or just shifted slightly in time).
So this means our task becomes that of coming up with interesting sequences of numbers to feed into the soundcard. If we just put in one number and never change it, the speaker cone will move to that position and stay there, resulting in maybe a small pop and then silence. Interesting stuff happen only when we repeatedly change the number according to some pattern.
In practical terms, and somewhat ironically, you can't really expect a modern computer to maintain a steady enough timed loop for it to explicitly send out each number to the soundcard. Instead, the standard way of doing it is to supply a long sequence of numbers, maybe a few hundred, to the soundcard at once, and then the soundcard goes through that sequence with exact timing and feeds each number to the D/A converter. This all happens at a predetermined rate, usually at 44100 samples per second (a sample is one of these numbers) for CD-quality audio. This sample rate is sometimes referred to as "Hz", even though it's not technically describing actual back-and-forth (oscillating) motion.
When the soundcard has processed all of the samples provided, it requests a new sequence (or buffer). In practice it will start out by requesting at least two, and then ask for a new buffer each time the oldest one is depleted, so that it always has a supply of samples to process. If the application for some reason can't deliver a requested buffer in time (maybe it takes too long to calculate it) before the soundcard has chewed through all the old ones, there will be periodic breaks in the sound output and you will hear crackling.
A simple waveform
All right, we need to come up with numbers. Repeating patterns of numbers. How on earth do we do that? Well, it's absolutely trivial - any repeating pattern of numbers will create an audible waveform (if you make them span a large enough range, going between 0.0 and 0.00001 is hardly going to catch anyone's attention).
* Any pattern you say? Well, what about 1,0,1,0,1,0,1,0,...?
Yeah, that'll work. But unfortunately you won't hear that one either, even though it's using a large part of the range. Remember that the samples are fed out through the D/A converter at 44100 per second, and those numbers describe an oscillation (back-and-forth, remember?) similar to this:
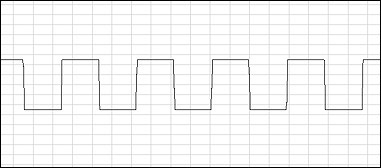
...but the pattern repeats itself every two samples, so the resulting speaker oscillation is at 22050 Hz. That's just above 20 kHz which you may recall as the upper limit for human hearing. That's actually the reason for using 44.1 kHz as the sample rate - so we can reproduce sounds over the entire range of the human ear, but not more (because that would be a waste).
* Sigh. Ok, what if I hold each of the numbers for a while before changing?
You mean something like 1,1,1,1,1,0,0,0,0,0,1,1,1,1,1,0,0,0,0,0,...?
* Yeah, like that. Or even more of the same before changing.
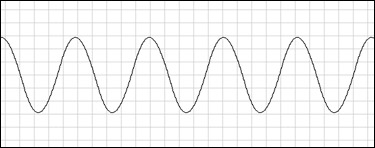
Whee, you've just created a square wave, which is probably the most classic digitally synthesized waveform. There's suddenly an element of control here: How many times do we repeat a number before changing to the other one? If we increase that count, the waveform will be more stretched out in time, and the oscillations will be slower since it takes more time to complete a full back-and-forth. The repeat count (also called "period" if measured in time) is a direct way of controlling the frequency of the tone that we are generating. A longer period means a lower frequency and vice versa.
 square.mp3 square.mp3
A small note of worth here is that you generally want a waveform to oscillate evenly around the zero-point, otherwise there will be an audible pop/click at the start and end of the tone. This is caused by the average signal level being shifted suddenly. It is illustrated rather clearly by how audio systems are constructed. They usually filter out anything that moves slower than a handful of Hz, to always keep the speaker cone oscillating around the physical rest point of the speaker. This is so you'll get the maximum available movement range out of it, even if your audio signal has a DC offset (meaning a rest level other than actual zero).
In our case, even if we tell it to oscillate between 0 and 1 (which means a center point of 0.5) it will pretty soon shift down so that it swings between -0.5 and +0.5. This is done by moving the entire signal range, so when you stop the tone, your zero level will still be shifted down by 0.5, but now that means that your nice and silent zero signal is actually output as -0.5, and it will slowly creep back to zero again within half a second or so. Basically your tone will be accompanied by a pop in the beginning as your zero level suddenly hops up to +0.5 and then a pop at the end when it jumps from 0.0 (after being adjusted) to -0.5.
So we should instead make our square waves consist of positive and negative numbers of the same magnitude. For example -0.5 to +0.5 or -1.0 to +1.0 (if we want it twice as loud).
Sine wave
While the square wave has the nice property of being very simple to describe with a digital computer, it is in fact very complex from an auditory or musical view. It contains a lot of resonant frequencies above the one we create by selecting the period length, which can make it sound "full" and characteristic. Actually some may describe it more as "hollow" or "airy", but it's still got character.
From a physical standpoint, the simplest waveform is the sine wave. It is quite simply a description of ideal oscillation similar to the kind you can get from a pendulum or a weight suspended by a spring, for instance. Objects tend to prefer this shape of movement when they're swinging back and forth across a midpoint.
Subjectively, a sine wave is rather dull as it can only be described as a very pure tone and nothing else. For making the cleanest possible sound it has some merit, and it's also useful as a component in building more complex sounds. Most of all it's an important theoretical and mathematical construct.
sine.mp3
A sine wave is somewhat complex to generate computationally, but in most cases there will be a sin() function providing it at a reasonable speed (and in an easy-to-use manner). A full oscillation period of sin(t) is attained by cycling t through the values 0.0 to 2*pi (which is approximately 6.283), and it outputs values ranging from -1.0 to +1.0. The reasoning for using such a seemingly odd parameter range is mathematical and related to the circle, traditional home of both sine and cosine. A circle of radius 1 has a circumference of exactly 2*pi.
Triangle
A triangle wave is an attempt to mimic the sine wave more closely than you could with square, but still using rather simple calculations. It is just a rising and falling ramp of values. The result does sound very much like a sine wave, so in that sense it's useful. Still sounds boring though, naturally.
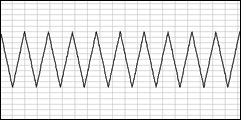
triangle.mp3
Sawtooth
This is half a triangle wave, resetting back to the starting value right when it reaches the top. From that jump in signal level you get a harsh quality similar to the square wave, but there's only one such jump in a period (compared to the square, which has two - both up and down) and the rest of it is smoothly shaped, so it tends to sound a bit warmer and more organic than the square.
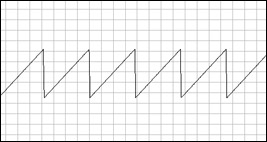
sawtooth.mp3
Noise
If you want more chaotic sounds, resembling explosions or general thrashing, you won't have much luck with simple repeating patterns (unless you vary them a lot, and then they cease to be simple repeating patterns). A straight-forward way of getting chaotic patterns is to employ a random number generator. Most programming languages have one. In C you would do something like this:
next_number = (float)(rand()%20000-10000)/10000
...to get a random number between -1.0 and +1.0. Look up rand() and srand() for details.
Despite this pattern being completely random and without order, you can still control the apparent "frequency" or lightness of the sound. This can be done in several ways, but the simplest is to delay the switch to a new random value based on whatever quality you're after. It is very similar to the square wave in that respect, except you will have to keep the period lengths much shorter for noise.
noise.mp3
General waveforms (for programmers)
To try out different kinds of waveforms using the same basic control code, you can keep a variable that will pass from 0.0 to 1.0 and wrap around for each full period of the sound. This period length would be determined by your desired frequency. To get the actual sample values, you can use different functions (depending on what waveform you want) to look up a suitable value based on the current period position.
For square, you would just check if it's less than or greater than 0.5. If it's less, you output -1.0, else +1.0 (or the other way around). To get a sawtooth, you just output something like (-1.0+period_pos*2.0), which will result in a signal ramp from -1.0 to +1.0 over the {0.0 - 1.0} period position range.
One thing I've found useful for noise is to regenerate a buffer of random samples each time the period counter wraps around, and continuously read out values from that buffer based on the current position within a period. You can choose the size of the buffer to be some suitable value, based on which frequency values you want to use. It doesn't have to be long but a few hundred samples is probably a good idea to avoid recomputing it all the time.
To change sound frequency you just set a new value for period length (though this will only affect the rate at which period position increments, it will always span between 0.0 and 1.0). For controlling volume you multiply the output sample by a volume value (say between 0.0 for silence and 1.0 for maximum volume). You can also mix several independent waveforms by adding their samples together, though make sure that you're not exceeding the allowed range of your soundcard (which would probably be the familiar -1.0 to +1.0 range). In other words, you'll have to use a lower volume for each waveform (or "channel") if you are going to mix (add) several of them together... or you can just multiply the final sum with a master volume value if you don't need volume control over each individual channel. This saves some multiply operations.
Another small heads-up worth considering is that you shouldn't use floating point numbers as if they were integral datatypes. That is; don't increment them in small steps over a large range. They have limited precision and will misbehave if you do that. It can manifest itself as a slight but noticable change in pitch or worse. You can increment floats as long as you keep them within a reasonable range, like between 0.0 and 1.0. The problems occur when the size of increments is much smaller than the current value (for example 50000.0 + 0.1).
If you have to increment over a large range, it is better to increment an integer and cast it to float whenever needed. Such a typecast might have a slight performance hit though. It is of course also possible to do all computations using only integer math, but that can be rather uncomfortable and hard to maintain for more complex sounds. Modern computers are fast enough at floating point math that you can usually afford this luxury.
This would be a simple way of handling the period positioning with floats:
float frequency
float volume
float period_speed
float period_position
init()
{
frequency = 440.0 // this is in Hz
period_speed = frequency/44100.0 // assuming a sample rate of 44.1 kHz
period_position = 0.0
}
fill_stream_buffer() // called by the soundcard
{
for(all samples in buffer)
{
period_position += period_speed
if(period_position >= 1.0) // change the "if" to a "while" if you expect frequencies above 44.1 kHz
{
period_position -= 1.0
}
this_sample = WaveformLookup(period_position)*volume
}
}
Note that we keep the period_position value between calls to fill_stream_buffer, so there will be no breaks or discontinuities in the waveform. If the last buffer ended with a period_position of 0.725 then the next one will start naturally from there and the output audio will sound continuous.
Dynamic waveforms
Even with the basic waveforms mentioned earlier, you can increase complexity and interest by varying different parameters over time. The only parameters that all of them have in common are frequency and volume, but even those two allow some rather interesting effects.
Besides simply setting a new fixed value, the simplest parameter "modulation" (alteration) is a simple ramp, or increasing/decreasing value. It is of course achieved by gradually incrementing or decrementing the parameter you're interested in. If you do this for volume you get a fade in or out, depending on the direction. For frequency the result is a frequency or pitch slide, naturally.
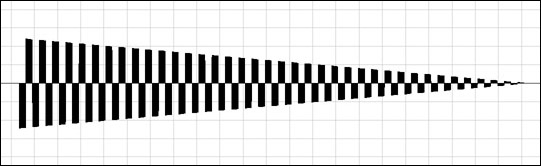
volume-ramp-up-down.mp3
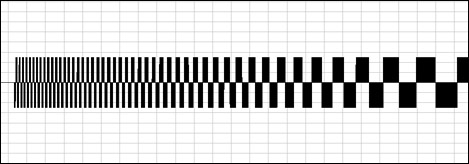
frq-ramp.mp3
You don't have to limit yourself to a single ramp, either. You can string several of them together, back-to-back. For instance: First fade in quickly, then maintain one volume level for a while, then fade out slowly. This is the basic idea of an "envelope", or scripted sound modulation. It is a simple and effective way of simulating the way natural sounds tend to vary in quality over time on a larger scale.
As an example we could hit a gong or empty barrel. The sound would start out strong and then continue by itself for a while, growing ever fainter until it can no longer be heard. Google "ADSR envelope" for more information.
I'll take this opportunity to point out that the square wave actually has an additional natural parameter associated with it - the duty cycle. This is the value describing the length relation between the first and second halves of the waveform period, or the midpoint position (0.5 in the earlier example). By changing this, you can dramatically change the sound character. Sweeping it gradually makes for a great effect in itself and is heavily used in C64 music and sfx.
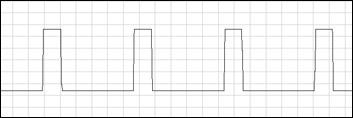
duties.mp3
Analyzing some typical sound effects
Many sounds used to represent various events are not arbitrary, but actually based on real associations we have to sounds in the real world, or more abstract ways in which we associate qualities of sound with different emotions or otherwise.
In sfxr it is common to just generate random sounds until one is encountered that somehow feels relevant or interesting. Sometimes it could be interpreted in some way to explain why it feels right, but that's of course not necessary if you just want a sound to go with something. If you want to manually create and adjust sounds for a specific purpose though, it might be useful to consider some deeper (or not) meanings which can be attributed to different sound properties.
To be honest, I made most of this stuff up as I wrote it, but it seems to make some kind of sense, and you might find some inspiration among the nonsense.
Coin
The classic Super Mario coin effect actually uses the "set new value" form of modulation. It starts out as a square wave of some frequency, then after a set amount of time it switches up to a brighter one which then proceeds to fade out using a downward volume ramp.
The fade-out mimics the natural decay of a physical object that is hit and set into oscillation (take a gong-gong for instance). Energy is always lost over time (converted into heat), so any self-maintained motion (or sound, which is motion of course) will gradually decay until it stops.
Here is a rough sketch of such a sound (the scale is way off, just illustrating the overall structure):

coin.mp3
Jump
Using Mario again, the good old jump sound is obviously a tone sliding up. It's actually a square with a non-neutral duty cycle though, which gives it more of a vocal quality than a simple "pure" square wave.
An interesting interpretation of the reason for using an upward slide might be to put it in the context of language. Most languages use upwards "sliding" to indicate interest or enthusiasm. Someone happily asking "Really?" in response to a positive statement from someone would do so going up on the second syllable.
Death
I can't come up with a specific example of this, but I have the sense that a general dark downward slide is used in some games to indicate failure or death. I just wanted to put this in relation to the upward slide mentioned above. Same language rules apply as we could utter an "Awww..." or similar as response to a negative statement. Also, going down in frequency does communicate the actual feeling of downward movement, which is also associated with defeat and feeling sad.
Laser shot
Most "laser" sounds (the Hollywood kind which is a slow projectile and not a continuous beam of light) are made from a simple downward slide, but a pretty fast one. Much faster than could be associated with language. Instead it starts entering the territory of physical phenomena, like a ricochette or noisy object moving away quickly (doppler effect).
Explosion
A real explosion is a very fast and chaotic reaction where some object or substance expands violently and disturbing the surrounding air while doing so. There's no tone to speak of, just a random crackling. Of course the most suitable source waveform to use for this effect is the noise, usually combined with some form of downward volume fade to mimic the naturally occuring decay and reverb that is usually associated with an explosion (noticable for things like distant gunshots and really large explosions).
Problems with numerical synthesis
We've already touched on the problems of pops caused by DC offset (the square wave going between 0.0 and 1.0), and the fact that you need to calculate sound buffers fast enough to feed the soundcard.
Another important aspect to consider is aliasing or distortion caused by the limited time precision available from using 44100 samples per second. Say you want a square wave with a period length of 17.3 samples - what to do? If you round it to 17 samples then it will have a significantly different resulting frequency. You wouldn't be able to do smooth frequency slides, at least not with bright sounds.
One way of dealing with it is to use floating point numbers for stepping through the period, which was shown earlier. Then you would get some train of alternating periods 17 and 18 samples in length. This would result in the correct overall frequency, but there would be audible distortion from the varying period lengths (in case of square this would be like changing the duty cycle back and forth by a small amount).
To reduce this distortion you can use a higher sample rate (say 4 times higher than what the sound card will output) and average nearby samples together to get the actual used rate before you hand over the buffer. This will result in antialiasing which has the effect of simulating a higher resolution using what you've got (same reason why sloping edges in digital photographs don't look stepped and pixelated).
This will of course take some more processing time (potentially 4x as much) and might not be feasible for more complex sounds. A modern computer can perform some few billion calculations in one second though, so that is quite a lot per sample at 44100 samples per second...
Sound capabilities of some classic systems
Ok, just a quick blurb here for now. Might elaborate at some point, but there are lots of very detailed sources for this information.
NES
- 4-bit DACs (16 signal levels)
- square (3 possible duty cycle settings, 50/50, 25/75, 12.5/87.5)
- triangle (fixed volume, using all 16 DAC levels)
- noise (actually 1-bit FM, random delay between flips)
- 1-bit DPCM (sampled sound, like triangle, can go up or down to follow original waveform)
C64
- much more flexible than NES
- 3 configurable channels
- analog filters
|
|
|
|
|
|
|
 |
|
|
|









